四. Replication 复制
The replication problem is one of many problems in distributed systems. I’ve chosen to focus on it over other problems such as leader election, failure detection, mutual exclusion, consensus and global snapshots because it is often the part that people are most interested in. One way in which parallel databases are differentiated is in terms of their replication features, for example. Furthermore, replication provides a context for many subproblems, such as leader election, failure detection, consensus and atomic broadcast.
复制是分布式系统中非常关键的一个点。下面将会从leader election、failure detection、mutual exclusion、consensus及global snapshots这些大家关心的问题展开介绍。区别并行数据库的一种方式是更具复制集的特征。
Replication is a group communication problem. What arrangement and communication pattern gives us the performance and availability characteristics we desire? How can we ensure fault tolerance, durability and non-divergence in the face of network partitions and simultaneous node failure?
复制是一组通信的问题。当网络发生分区或者节点同时崩溃时,怎样保证系统的容错性、持久性和非发散性?
Again, there are many ways to approach replication. The approach I’ll take here just looks at high level patterns that are possible for a system with replication. Looking at this visually helps keep the discussion focused on the overall pattern rather than the specific messaging involved. My goal here is to explore the design space rather than to explain the specifics of each algorithm.
复制的方式有很多种,这里并不对每种算法进行详细的介绍,只是进行一个方法的汇总讨论
Let’s first define what replication looks like. We assume that we have some initial database, and that clients make requests which change the state of the database.
首先,到底什么是复制集呢?我们认为,当我们拥有初始数据库时,客户通过一定的请求操作会改变数据库的状态
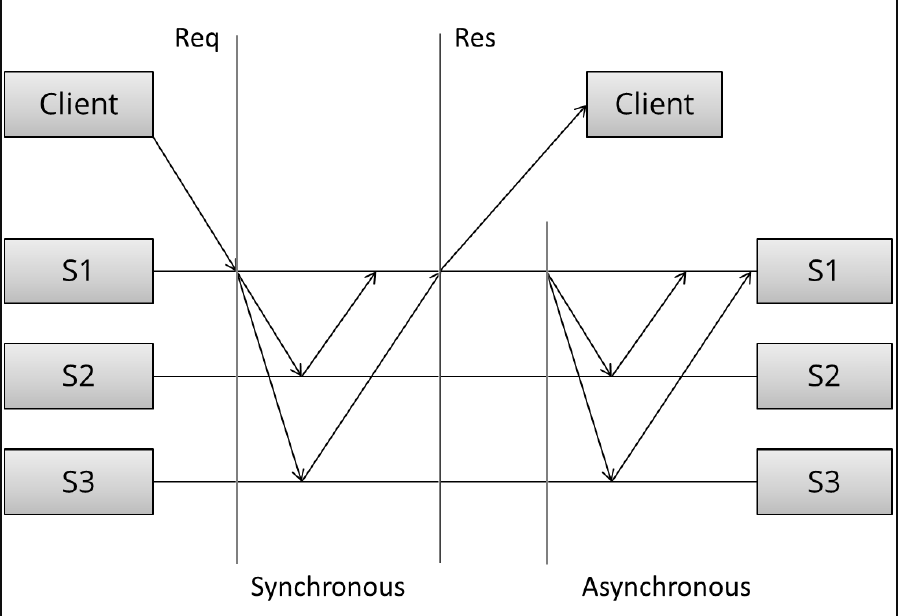
The arrangement and communication pattern can then be divided into several stages:
- (Request) The client sends a request to a server
- (Sync) The synchronous portion of the replication takes place
- (Response) A response is returned to the client
- (Async) The asynchronous portion of the replication takes place
This model is loosely based on this article. Note that the pattern of messages exchanged in each portion of the task depends on the specific algorithm: I am intentionally trying to get by without discussing the specific algorithm.
Given these stages, what kind of communication patterns can we create? And what are the performance and availability implications of the patterns we choose?
这个时候的处理和通信模式罗分为下面几个阶段:
- (Request)客户向服务发送一个请求
- (Sync)复制中的同步部分发生
- (Responses)向客户返回答复
- (Async)复制中的异步部分发生
在这些阶段中,通信模式是怎样的呢?
Synchronous replication 同步复制
The first pattern is synchronous replication (also known as active, or eager, or push, or pessimistic replication). Let’s draw what that looks like:
同步复制:悲观复制,接受到客户端的请求之后,各节点先同步并返回到此节点之后,再响应客户端

Here, we can see three distinct stages: first, the client sends the request. Next, what we called the synchronous portion of replication takes place. The term refers to the fact that the client is blocked - waiting for a reply from the system.
同步复制中有三个明确的阶段:首先,用户发送请求;接着,同步部分发生。这个时候用户是阻塞的-等待系统的回复的。
During the synchronous phase, the first server contacts the two other servers and waits until it has received replies from all the other servers. Finally, it sends a response to the client informing it of the result (e.g. success or failure).
在同步阶段,第一个服务器和另两个服务器之间进行通信,并且等到来自这两个服务器的回复后,最后将一个统一的结果告知客户(成功还是失败)
All this seems straightforward. What can we say of this specific arrangement of communication patterns, without discussing the details of the algorithm during the synchronous phase? First, observe that this is a write N - of - N approach: before a response is returned, it has to be seen and acknowledged by every server in the system.
可以观察到,同步复制必须要当结果被所有的服务节点认可后才会返回一个值给客户
From a performance perspective, this means that the system will be as fast as the slowest server in it. The system will also be very sensitive to changes in network latency, since it requires every server to reply before proceeding.
从性能的角度来看,这意味着系统最快的反应时间取决于最慢的一个服务节点。这样的系统会对网络延迟非常敏感。
Given the N-of-N approach, the system cannot tolerate the loss of any servers. When a server is lost, the system can no longer write to all the nodes, and so it cannot proceed. It might be able to provide read-only access to the data, but modifications are not allowed after a node has failed in this design.
这就是N-of-N write架构,只有等所有N个节点成功写,才返回写成功给client。系统将不能忍受任一个服务节点发生数据丢失的情况。一旦有一个服务节点发生丢失,系统将不允许对数据进行写操作。同时修改操作也不会被允许,只会允许进行读操作
This arrangement can provide very strong durability guarantees: the client can be certain that all N servers have received, stored and acknowledged the request when the response is returned. In order to lose an accepted update, all N copies would need to be lost, which is about as good a guarantee as you can make.
这样能提供一个非常长的持久性保证:客户能够确保所有的服务节点都接收到了请求,并且对请求做出响应。只有当所有节点上的副本都丢失了,更新的数据才会丢失
Asynchronous replication 异步复制
Let’s contrast this with the second pattern - asynchronous replication (a.k.a. passive replication, or pull replication, or lazy replication). As you may have guessed, this is the opposite of synchronous replication:
异步复制:积极复制、拉复制、惰性复制,接受到客户端的请求之后,先响应客户端,再进行各节点先同步并且返回到此节点
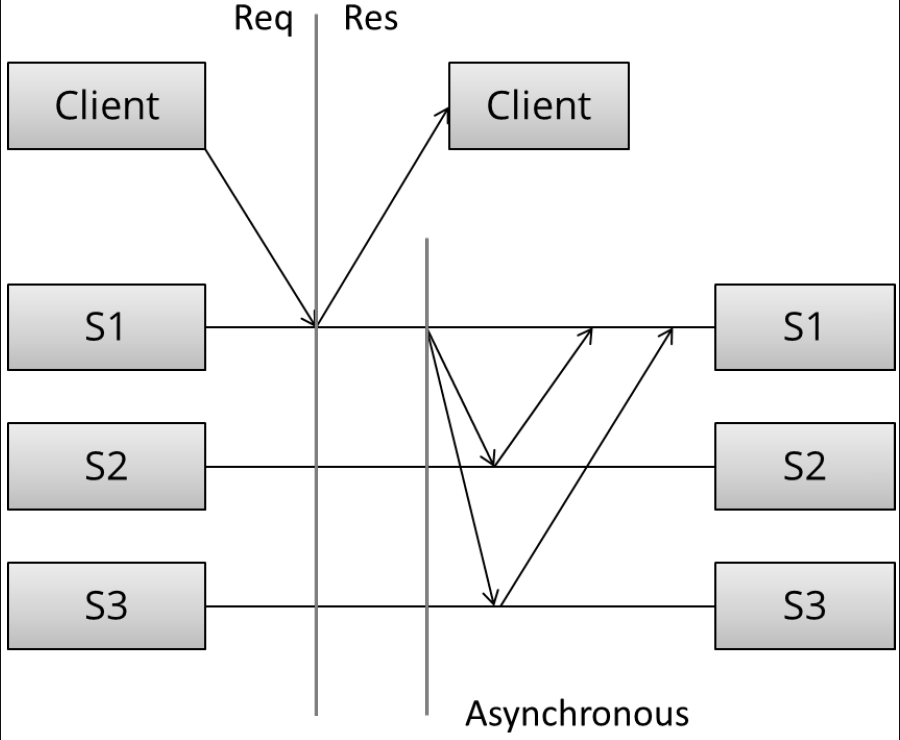
Here, the master (/leader / coordinator) immediately sends back a response to the client. It might at best store the update locally, but it will not do any significant work synchronously and the client is not forced to wait for more rounds of communication to occur between the servers.
这里,主节点先快速响应客户端。先局部快速存储更新,但是不会严格同步。客户端不需要等待所有结果完成后才能收到回复
At some later stage, the asynchronous portion of the replication task takes place. Here, the master contacts the other servers using some communication pattern, and the other servers update their copies of the data. The specifics depend on the algorithm in use.
在接下来的阶段,复制的异步部分发生。主节点利用通信模式对其它服务节点进行交流,接着其它节点对复制集进行更新。具体实施过程依赖于所选择的算法
What can we say of this specific arrangement without getting into the details of the algorithm? Well, this is a write 1 - of - N approach: a response is returned immediately and update propagation occurs sometime later.
那么抽象而言,异步复制就是一个 write 1 - of - N 的架构:立刻响应客户端,再接着进行各节点的更新同步
From a performance perspective, this means that the system is fast: the client does not need to spend any additional time waiting for the internals of the system to do their work. The system is also more tolerant of network latency, since fluctuations in internal latency do not cause additional waiting on the client side.
从性能的角度来看,这样的系统通常更快,因为客户端不需要等到所有的节点同步完成后才得到响应。同时这样的系统对于网络延迟的容忍性更高。
This arrangement can only provide weak, or probabilistic durability guarantees. If nothing goes wrong, the data is eventually replicated to all N machines. However, if the only server containing the data is lost before this can take place, the data is permanently lost.
这样的操作只能提供一个弱的,某种程度上的持久性保证。如果没有任何故障发生,数据最终在N台机器上的复制集都会保持一致。但一旦数据只在一台服务器上,这个服务器发生数据丢失的话,数据将会永久丢失(持久性:对数据所做的更改能够永久保存下来)
Given the 1-of-N approach, the system can remain available as long as at least one node is up (at least in theory, though in practice the load will probably be too high). A purely lazy approach like this provides no durability or consistency guarantees; you may be allowed to write to the system, but there are no guarantees that you can read back what you wrote if any faults occur.
在异步复制中,系统只需要得到一个节点的响应就能保证它的可用性(理论上是这样,但是在现实中,实践中负载通常会很高,单位时间内承受的工作量大)。像这样的惰性复制不会保证持久性和一致性:你能够对数据进行写操作,但是一旦错误发生,不一定保证你能读到你所写的东西
Finally, it’s worth noting that passive replication cannot ensure that all nodes in the system always contain the same state. If you accept writes at multiple locations and do not require that those nodes synchronously agree, then you will run the risk of divergence: reads may return different results from different locations (particularly after nodes fail and recover), and global constraints (which require communicating with everyone) cannot be enforced.
积极复制不能保证系统中所有的节点都能保持在同样的状态。如果你在多个机器进行写操作,并且又不要求这些节点同步做出确定,那么很有可能造成数据不一致的结果:从不同位置上读取数据可能返回的是不同的值(尤其是节点发生故障后恢复之后),并且不能进行强制全局限制(需要各个节点进行通信)
I haven’t really mentioned the communication patterns during a read (rather than a write), because the pattern of reads really follows from the pattern of writes: during a read, you want to contact as few nodes as possible. We’ll discuss this a bit more in the context of quorums.
We’ve only discussed two basic arrangements and none of the specific algorithms. Yet we’ve been able to figure out quite a bit of about the possible communication patterns as well as their performance, durability guarantees and availability characteristics.
An overview of major replication approaches 主要的复制方法
Having discussed the two basic replication approaches: synchronous and asynchronous replication, let’s have a look at the major replication algorithms.
刚刚讨论了什么是同步复制和异步复制,现在来介绍相关的主要的复制算法
There are many, many different ways to categorize replication techniques. The second distinction (after sync vs. async) I’d like to introduce is between:
- Replication methods that prevent divergence (single copy systems) and
- Replication methods that risk divergence (multi-master systems)
两种复制方法:
- single copy systems 单拷贝系统:阻止数据不一致的复制方法
- multi-master systems 多master系统:有数据不一致风险的复制方法
The first group of methods has the property that they “behave like a single system”. In particular, when partial failures occur, the system ensures that only a single copy of the system is active. Furthermore, the system ensures that the replicas are always in agreement. This is known as the consensus problem.
单拷贝系统复制方法表现的形式像单个系统一样。当局部发生故障时,系统保证只有一个系统单副本处于活跃状态。进一步说,就是系统保证复制集永远处于一致的状态。
Several processes (or computers) achieve consensus if they all agree on some value. More formally:
- Agreement: Every correct process must agree on the same value.
- Integrity: Every correct process decides at most one value, and if it decides some value, then it must have been proposed by some process.
- Termination: All processes eventually reach a decision.
- Validity: If all correct processes propose the same value V, then all correct processes decide V.
服务进程统一统一某个值后才达成一致性,一致性定义具体如下:
- Agreement:所有正确进程必须做出相同的决议
- Integrity:每个正确的进程最多承认一个值,一旦一个进程决定了某一个值,那么这个值肯定是被其它进程提出的
- Termination:所有正确的进程最终都会同意某个值
- Validity:如果所有正确的进程提出相同的值V,那么所有正确的节点进程达成一致,承认值V
Mutual exclusion, leader election, multicast and atomic broadcast are all instances of the more general problem of consensus. Replicated systems that maintain single copy consistency need to solve the consensus problem in some way.
leader election、failure detection、mutual exclusion、consensus及global snapshots这些都会涉及到一致性问题。保证单拷贝一致性的复制系统需要解决这些问题
The replication algorithms that maintain single-copy consistency include:
- 1n messages (asynchronous primary/backup)
- 2n messages (synchronous primary/backup)
- 4n messages (2-phase commit, Multi-Paxos)
- 6n messages (3-phase commit, Paxos with repeated leader election)
单拷贝一致性复制算法包括:
(这些算法的容错性都各自不同。根据执行过程中的信息交互数量对这些算法进行了一个分类)
- 1n messages(异步 主/备)
- 2n messages(同步 主/备)
- 4n messages(2阶段提交,多-Paxos)
- 6n messages(3阶段提交,进行leader选举的Paxos)
These algorithms vary in their fault tolerance (e.g. the types of faults they can tolerate). I’ve classified these simply by the number of messages exchanged during an execution of the algorithm, because I think it is interesting to try to find an answer to the question “what are we buying with the added message exchanges?”
The diagram below, adapted from Ryan Barret at Google, describes some of the aspects of the different options:
Ryan Barret对这些算法进行了一个不同层面的比较:
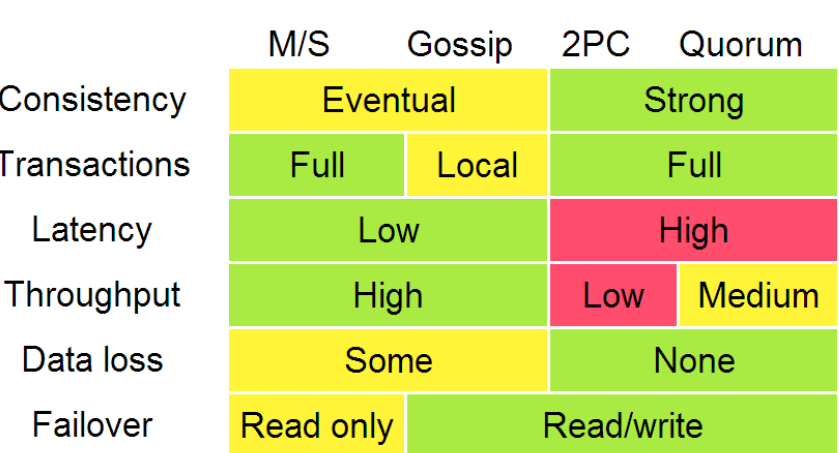
The consistency, latency, throughput, data loss and failover characteristics in the diagram above can really be traced back to the two different replication methods: synchronous replication (e.g. waiting before responding) and asynchronous replication. When you wait, you get worse performance but stronger guarantees. The throughput difference between 2PC and quorum systems will become apparent when we discuss partition (and latency) tolerance.
上图中从一致性、延迟性、吞吐量、数据丢失、失败等特征通过对同步和异步复制过程来对这些算法进行了一个比较。当你处于等待状态时,系统性能不高但是有高保证。
In that diagram, algorithms enforcing weak (/eventual) consistency are lumped up into one category (“gossip”). However, I will discuss replication methods for weak consistency - gossip and (partial) quorum systems - in more detail. The “transactions” row really refers more to global predicate evaluation, which is not supported in systems with weak consistency (though local predicate evaluation can be supported).
在这个图中,算法保证低一致性(最终一致性)都集中在一种类型(gossip)上。这一节不讨论低一致性。(The “transactions” row really refers more to global predicate evaluation, which is not supported in systems with weak consistency (though local predicate evaluation can be supported谓词运算:True or False+运算操作)
It is worth noting that systems enforcing weak consistency requirements have fewer generic algorithms, and more techniques that can be selectively applied. Since systems that do not enforce single-copy consistency are free to act like distributed systems consisting of multiple nodes, there are fewer obvious objectives to fix and the focus is more on giving people a way to reason about the characteristics of the system that they have.
弱一致性通用的算法很少,一般都是根据需求选择。当系统不再强制要求单拷贝一致性时,它会更加灵活,表现得更加像分布式系统。
For example:
- Client-centric consistency models attempt to provide more intelligible consistency guarantees while allowing for divergence.
- CRDTs (convergent and commutative replicated datatypes) exploit semilattice properties (associativity, commutativity, idempotency) of certain state and operation-based data types.
- Confluence analysis (as in the Bloom language) uses information regarding the monotonicity of computations to maximally exploit disorder.
- PBS (probabilistically bounded staleness) uses simulation and information collected from a real world system to characterize the expected behavior of partial quorum systems.
I’ll talk about all of these a bit further on, first; let’s look at the replication algorithms that maintain single-copy consistency.
例如:
- 客户端为中心的一致性模型当发生数据不一致的时候,会尝试提供更易于理解的一致性保证
- CRDTs(一致复制集数据类型):一种拥有结合性、交换性、幂等性的操作数据类型
- 整合分析(如在Bloom语言中)使用关于计算的单调性的信息来最大限度地利用无序。
- PBS(probabilistically bounded staleness)使用仿真和从真实世界系统收集的信息来刻画部分仲裁系统的预期行为。
后面会进行更深入的讨论。第四节主要关注单拷贝一致性的复制算法
Primary/backup replication 主备复制
Primary/backup replication (also known as primary copy replication master-slave replication or log shipping) is perhaps the most commonly used replication method, and the most basic algorithm. All updates are performed on the primary, and a log of operations (or alternatively, changes) is shipped across the network to the backup replicas. There are two variants:
- asynchronous primary/backup replication and
- synchronous primary/backup replication
主备复制(主从复制、日志传输复制)是最常用的复制算法,也是最基本的复制算法。所有的更新都在主节点上进行,然后通过网络传送日志操作到其他节点副本中。这里有两种类型:
- 异步主从复制:只需一条信息(更新)
- 同步主从复制:需要两条信息(更新+确定收到)
The synchronous version requires two messages (“update” + “acknowledge receipt”) while the asynchronous version could run with just one (“update”).
P/B is very common. For example, by default MySQL replication uses the asynchronous variant. MongoDB also uses P/B (with some additional procedures for failover). All operations are performed on one master server, which serializes them to a local log, which is then replicated asynchronously to the backup servers.
主从复制例子:MySQL(异步)、MongoDB(有一些额外的故障备援方案)。所有的操作都在主服务器上进行,连载操作的日志信息然后异步更新到其它的备份节点中
As we discussed earlier in the context of asynchronous replication, any asynchronous replication algorithm can only provide weak durability guarantees. In MySQL replication this manifests as replication lag: the asynchronous backups are always at least one operation behind the primary. If the primary fails, then the updates that have not yet been sent to the backups are lost.
像之前讨论的异步复制中,任何异步复制的算法都只能保证弱持久性。在MySQL复制中它的表现形式为复制滞后:异步复制的节点备份通常在主节点操作之后,一旦主机发生故障,数据更新日志可能发生丢失
The synchronous variant of primary/backup replication ensures that writes have been stored on other nodes before returning back to the client - at the cost of waiting for responses from other replicas. However, it is worth noting that even this variant can only offer weak guarantees. Consider the following simple failure scenario:
- the primary receives a write and sends it to the backup
- the backup persists and ACKs the write
- and then primary fails before sending ACK to the client
主从复制的同步类型能够保证写操作在返回消息给客户端之前,每个节点上都会存储写信息,同时带来的副作用是需要等待复制的时间。但是尽管这种同步类型的主从复制系统提供的是弱保证,也没有什么影响。思考下面这些失败的场景案例:
- 主节点收到写操作,并且将这个命令发送给从节点
- 从节点收到并且对这个写操作做出命令正确应答的回应(ACKs)
- 主节点在发送ACK(命令正确应答)给客户端之前发生故障
The client now assumes that the commit failed, but the backup committed it; if the backup is promoted to primary, it will be incorrect. Manual cleanup may be needed to reconcile the failed primary or divergent backups.
这个时候客户端会猜测这次提交失败了,但是其实从节点已经正确提交了;如果备份节点提交了,但是主节点没有提交,即备份节点比主节点超前了,这样是错误的。这种矛盾需要进行协调
I am simplifying here of course. While all primary/backup replication algorithms follow the same general messaging pattern, they differ in their handling of failover, replicas being offline for extended periods and so on. However, it is not possible to be resilient to inopportune failures of the primary in this scheme.
之前提到过,系统都会有自己的失效备援操作,但是当主节点在这种场景下发生故障,系统是无法进行复原的
What is key in the log-shipping / primary/backup based schemes is that they can only offer a best-effort guarantee (e.g. they are susceptible to lost updates or incorrect updates if nodes fail at inopportune times). Furthermore, P/B schemes are susceptible to split-brain, where the failover to a backup kicks in due to a temporary network issue and causes both the primary and backup to be active at the same time.
主从复制中还有一个重要的关键点:日志传输。日志传输使得主从复制只能保证尽可能的正确,如果节点在不适宜的时间失败,可能会导致更新失败或数据丢失
To prevent inopportune failures from causing consistency guarantees to be violated; we need to add another round of messaging, which gets us the two phase commit protocol (2PC).
为了防止主从复制的不足,需要多加一轮消息传送认证,因此需要两个阶段提交协议(2PC)
Two phase commit (2PC) 两阶段提交
Two phase commit (2PC) is a protocol used in many classic relational databases. For example, MySQL Cluster (not to be confused with the regular MySQL) provides synchronous replication using 2PC. The diagram below illustrates the message flow:
两阶段提交(2PC)协议是关系数据库中最经典的一种协议。例如在MySQL集群中,就利用2PC协议来进行同步复制。下图中阐述了该复制过程中信息流的变化:
1 | [ Coordinator ] -> OK to commit? [ Peers ] |
In the first phase (voting), the coordinator sends the update to all the participants. Each participant processes the update and votes whether to commit or abort. When voting to commit, the participants store the update onto a temporary area (the write-ahead log). Until the second phase completes, the update is considered temporary.
在第一个表决阶段(voting),协调者向所有的参与者发送更新消息。每一个参与者处理更新操作并表决是否提交或是终止,当表决结果是提交时,这些参与者实际上会将更新放在一个暂时区域(写操作日志头)中,这些更新始终都是暂时的,直到第二个阶段完成
In the second phase (decision), the coordinator decides the outcome and informs every participant about it. If all participants voted to commit, then the update is taken from the temporary area and made permanent.
在第二个决策阶段(decision),协调者决定最后的结果,并且告知所有的参与者。如果所有的参与者第一阶段的表决都是提交,那么更新操作才会进行持久化。
Having a second phase in place before the commit is considered permanent is useful, because it allows the system to roll back an update when a node fails. In contrast, in primary/backup (“1PC”), there is no step for rolling back an operation that has failed on some nodes and succeeded on others, and hence the replicas could diverge.
在提交被认为是永久的之前,第二个阶段是非常有用的,因为它允许系统在节点失败时回滚更新。相反,在主/备份(“1PC”)中,没有回滚步骤,若发生在某些节点上失败而在其他节点上成功的情况,副本可能会出现分歧。
2PC is prone to blocking, since a single node failure (participant or coordinator) blocks progress until the node has recovered. Recovery is often possible thanks to the second phase, during which other nodes are informed about the system state. Note that 2PC assumes that the data in stable storage at each node is never lost and that no node crashes forever. Data loss is still possible if the data in the stable storage is corrupted in a crash.
2PC容易造成拥塞,因为一旦一个节点失败,无论是协调者或是参与者,都会导致进程拥堵,直到节点修复。修复过程一般需要依靠第二个阶段中其它节点被告知系统状态。2PC是假设各个节点中的数据处于一个稳定的存储状态中,数据永远不会丢失并且不会发生节点崩溃。但是数据就算存储稳定,仍然会发生丢失如果发生崩溃的现象
The details of the recovery procedures during node failures are quite complicated so I won’t get into the specifics. The major tasks are ensuring that writes to disk are durable (e.g. flushed to disk rather than cached) and making sure that the right recovery decisions are made (e.g. learning the outcome of the round and then redoing or undoing an update locally).
节点故障期间恢复过程非常复杂,因此我不想详细介绍。主要任务是确保对磁盘的写入是持久的(例如,刷新到磁盘而不是缓存),并确保做出正确的恢复决策(例如,得到回合的结果,然后在本地重做或撤消更新)
As we learned in the chapter regarding CAP, 2PC is a CA - it is not partition tolerant. The failure model that 2PC addresses does not include network partitions; the prescribed way to recover from a node failure is to wait until the network partition heals. There is no safe way to promote a new coordinator if one fails; rather a manual intervention is required. 2PC is also fairly latency-sensitive, since it is a write N-of-N approach in which writes cannot proceed until the slowest node acknowledges them.
正如我们在介绍CAP的章节中了解到的,2PC是一个CA算法,它没有分区容忍。2PC的故障模型中不包括网络分区;从节点故障恢复的指定方法是等待网络分区恢复。如果一个协调员失败了,就没有安全的方法来生成一个新的协调员;相反,需要人工干预。2PC还相当容易延迟,因为它是一种N对N的写方法,在最慢的节点确认之前,写操作无法继续。
2PC strikes a decent balance between performance and fault tolerance, which is why it has been popular in relational databases. However, newer systems often use a partition tolerant consensus algorithm, since such an algorithm can provide automatic recovery from temporary network partitions as well as more graceful handling of increased between-node latency.
2PC在性能和容错之间取得了相当好的平衡,这就是它在关系数据库中流行的原因。(因为失败了有回滚吗???)但是,较新的系统通常使用允许分区的一致性算法,因为这样的算法可以自动恢复由于临时网络分区造成的故障,以及能够对增加的节点间延迟时间进行更好的处理
Let’s look at partition tolerant consensus algorithms next.
接着来看分区容忍共识算法
Partition tolerant consensus algorithms 分区容忍一致性算法
Partition tolerant consensus algorithms are as far as we’re going to go in terms of fault-tolerant algorithms that maintain single-copy consistency. There is a further class of fault tolerant algorithms: algorithms that tolerate arbitrary (Byzantine) faults; these include nodes that fail by acting maliciously. Such algorithms are rarely used in commercial systems, because they are more expensive to run and more complicated to implement - and hence I will leave them out.
在保证单拷贝一致性中,考虑分区容忍一致性算法是我们将要讨论的内容。还有一类容错算法:允许任意(拜占庭式)错误的算法;这些算法来处理恶意操作导致节点失败的情况。这种算法很少在商业系统中使用,因为它们运行起来更昂贵,实现起来也更复杂——因此我将把它们排除在外。
When it comes to partition tolerant consensus algorithms, the most well-known algorithm is the Paxos algorithm. It is, however, notoriously difficult to implement and explain, so I will focus on Raft, a recent (~early 2013) algorithm designed to be easier to teach and implement. Let’s first take a look at network partitions and the general characteristics of partition tolerant consensus algorithms.
涉及到分区容忍一致性算法时,最著名的算法是Paxos算法。然而,众所周知,它很难实现和解释,所以我将重点关注Raft,这是一种最近(2013年初)的算法,旨在更易于教学和实现。让我们首先看一下网络分区和允许分区的共识算法的一般特性。
What is a network partition?什么是网络分区?
A network partition is the failure of a network link to one or several nodes. The nodes themselves continue to stay active, and they may even be able to receive requests from clients on their side of the network partition. As we learned earlier - during the discussion of the CAP theorem - network partitions do occur and not all systems handle them gracefully.
网络分区是指到一个或多个节点之间的网络链接失败。节点本身继续保持活动状态,甚至可以从网络分区的客户端接收请求。正如我们之前在讨论CAP定理中讨论到的,当网络分区发生后,并不是所有系统都能很好地处理它们。
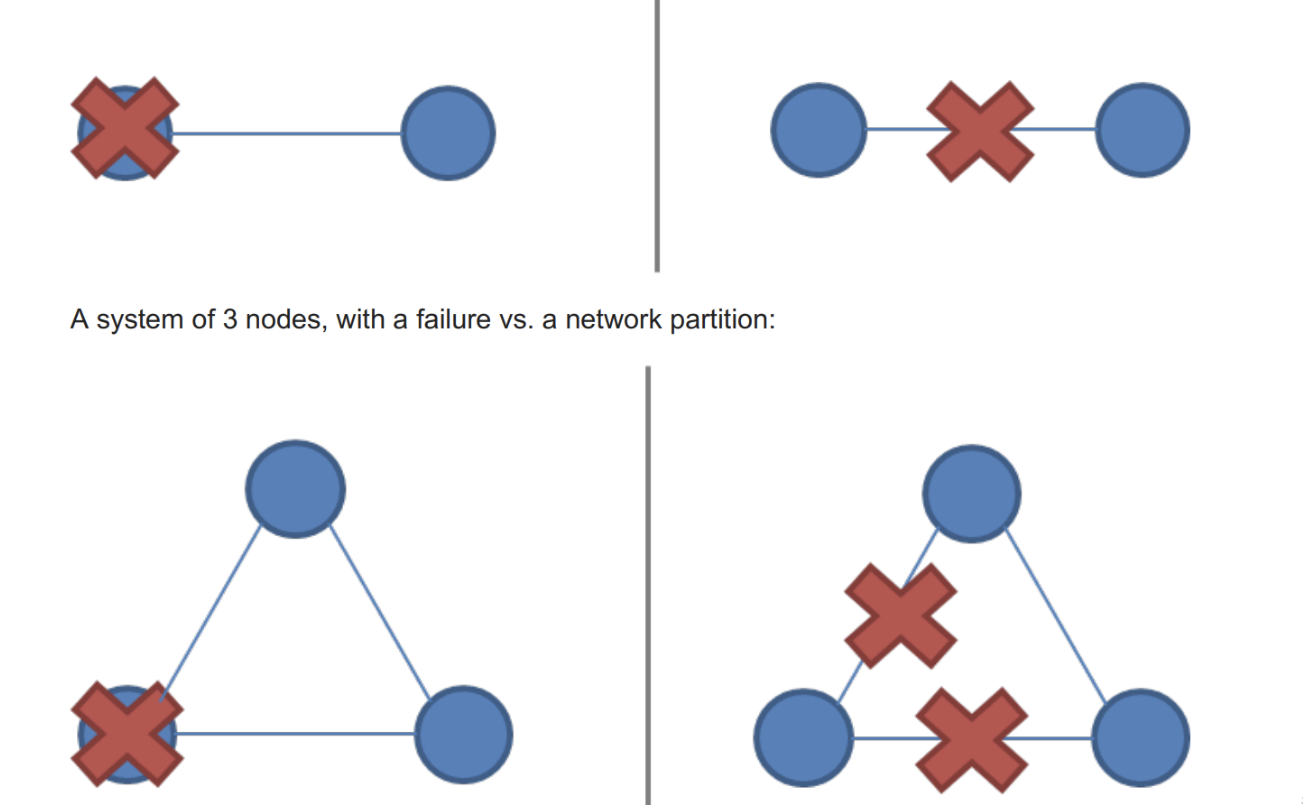
Network partitions are tricky because during a network partition, it is not possible to distinguish between a failed remote node and the node being unreachable. If a network partition occurs but no nodes fail, then the system is divided into two partitions which are simultaneously active. The two diagrams below illustrate how a network partition can look similar to a node failure.
网络分区很棘手,因为在网络分区期间,无法区分远程节点是发生了故障还是无法访问。如果一个网络分区出现但没有节点失败,那么系统将被划分为两个同时处于活动状态的分区。下面的两个图说明了网络分区看起来如何类似于节点故障。
A system of 2 nodes, with a failure vs. a network partition:
下图展示了由两个节点组成的系统。网络分区VS存在故障:
A system that enforces single-copy consistency must have some method to break symmetry: otherwise, it will split into two separate systems, which can diverge from each other and can no longer maintain the illusion of a single copy.
一个强制实现单一拷贝一致性的系统必须有某种方法来打破对称性:否则,它将分裂成两个独立的系统,这两个系统可以彼此分离,并且不能再保持单一拷贝的假象。
Network partition tolerance for systems that enforce single-copy consistency requires that during a network partition, only one partition of the system remains active since during a network partition it is not possible to prevent divergence (e.g. CAP theorem).
对于强制执行单一拷贝一致性的系统,网络分区容忍要求在网络分区期间,只有一个系统分区保持活跃状态,因为在网络分区不能保证数据不发生分歧(CAP定理)
Majority decisions 主要决策
This is why partition tolerant consensus algorithms rely on a majority vote. Requiring a majority of nodes - rather than all of the nodes (as in 2PC) - to agree on updates allows a minority of the nodes to be down, or slow, or unreachable due to a network partition. As long as (N/2 + 1)-of-N nodes are up and accessible, the system can continue to operate.
分区容忍一致性算法需要多数的投票
不同于2PC算法需要所有的节点都达到一致,这里只需要大多数节点能够同意更新并且容许少部分节点宕机、慢或者由于网络分区而无法接触,这样系统仍然能够继续运行
Partition tolerant consensus algorithms use an odd number of nodes (e.g. 3, 5 or 7). With just two nodes, it is not possible to have a clear majority after a failure. For example, if the number of nodes is three, then the system is resilient to one node failure; with five nodes the system is resilient to two node failures.
分区容忍一致性算法使用的是奇数节点(类似于3,5,7)
如果使用2个节点的话,那么就难以对多数投票中的多数进行定义。举例说明:如果节点数量是3个,那么系统能够允许一个节点失败;如果节点数是5个,系统能够允许2个节点失败
When a network partition occurs, the partitions behave asymmetrically. One partition will contain the majority of the nodes. Minority partitions will stop processing operations to prevent divergence during a network partition, but the majority partition can remain active. This ensures that only a single copy of the system state remains active.
当发生网络分区时,各个区的表现是不一致的。一个区可能包含大多数节点。小部分区会停止程序运行操作来阻止网络分区带来的数据分歧,但多数区仍然保持活跃状态。这能保证系统中只有一个单副本是活跃的
Majorities are also useful because they can tolerate disagreement: if there is a perturbation or failure, the nodes may vote differently. However, since there can be only one majority decision, a temporary disagreement can at most block the protocol from proceeding (giving up liveness) but it cannot violate the single-copy consistency criterion (safety property).
因为系统能够允许存在不一致,使得多数节点仍然是可用的:如果有变动和失败发生,节点可能投票不一致。但由于只可能有一个多数决策存在,暂时的分歧最多可以阻止协议继续进行(放弃活跃性),但不能违反单一副本一致性标准(安全属性)
Roles 角色
There are two ways one might structure a system: all nodes may have the same responsibilities, or nodes may have separate, distinct roles.
构造一个系统,系统中所有的节点要么含有相同的目标,要么有明确的分工和扮演的角色
Consensus algorithms for replication generally opt for having distinct roles for each node. Having a single fixed leader or master server is an optimization that makes the system more efficient, since we know that all updates must pass through that server. Nodes that are not the leader just need to forward their requests to the leader.
复制的一致性算法通常会对每个节点分配不同的角色。一个系统中有一个固定的领导节点或者主服务能够使这个系统更加高效,所有的更新操作都要经过这个主服务。不是领导的节点只需要将它们的请求附送给领导节点
Note that having distinct roles does not preclude the system from recovering from the failure of the leader (or any other role). Just because roles are fixed during normal operation doesn’t mean that one cannot recover from failure by reassigning the roles after a failure (e.g. via a leader election phase). Nodes can reuse the result of a leader election until node failures and/or network partitions occur.
注意,明确的角色不代表系统中所有的节点一直扮演一个类型的角色。如果系统从节点失败中恢复过来,那么节点的角色可能会被从新分配,这个时候会存在一个领导节点选举的阶段。节点扮演它们的角色,到节点发生失败或者网络发生分区的时候,角色将又重新定义。
Both Paxos and Raft make use of distinct node roles. In particular, they have a leader node (“proposer” in Paxos) that is responsible for coordination during normal operation. During normal operation, the rest of the nodes are followers (“acceptors” or “voters” in Paxos).
无论是Paxos算法还是Raft算法,它们都有明确的节点分工。具体而言,它们都有一个领导节点leader node(在Paxos中被称为proposer),负责正常系统运行操作中的协调作用。在正常运行中,剩下的节点是跟随节点follows(Paxos中称为acceptors或者voters)
Epochs 训练周期
Each period of normal operation in both Paxos and Raft is called an epoch (“term” in Raft). During each epoch only one node is the designated leader (a similar system is used in Japan where era names change upon imperial succession).
无论是Paxos还是Raft算法中,正常运行的每一个阶段都被称为一个训练周期(Raft中被称为‘term’)。在每一个周期中,只有一个节点被标记为领导节点(Leader)
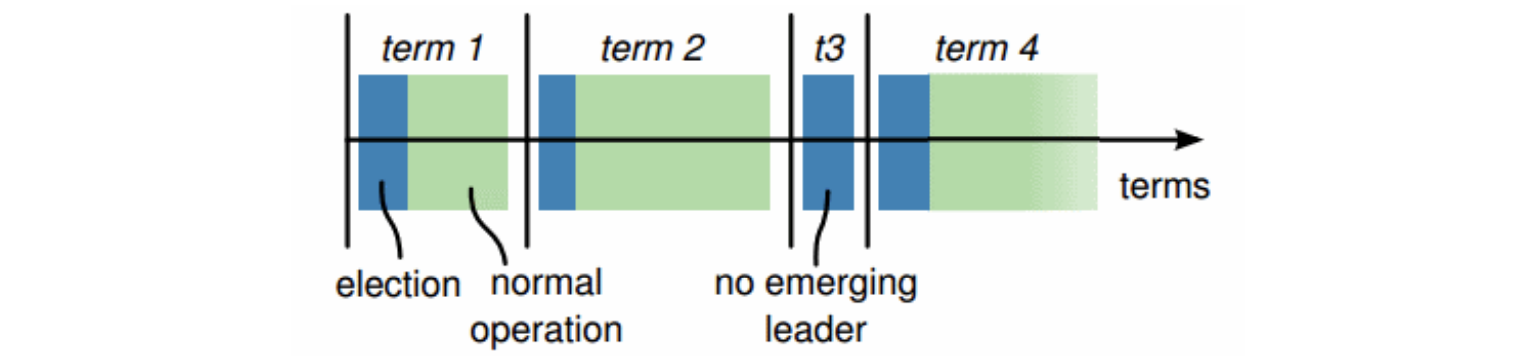
After a successful election, the same leader coordinates until the end of the epoch. As shown in the diagram above (from the Raft paper), some elections may fail, causing the epoch to end immediately.
成功选举后,在这个周期中领导节点不变,直到下一次选举发生。如图所示,可能会存在选举失败的情况,这个时候会导致这个周期很快结束
Epochs act as a logical clock, allowing other nodes to identify when an outdated node starts communicating - nodes that were partitioned or out of operation will have a smaller epoch number than the current one, and their commands are ignored.
周期纪元表现形式想逻辑锁一样,它允许其它节点识别出一个过期节点何时开始通信-分区或不运行的节点相比于正常的节点,周期会落后,能被识别出来并且它们的需求就直接被忽略
Leader changes via duels 领导节点变化
During normal operation, a partition-tolerant consensus algorithm is rather simple. As we’ve seen earlier, if we didn’t care about fault tolerance, we could just use 2PC. Most of the complexity really arises from ensuring that once a consensus decision has been made, it will not be lost and the protocol can handle leader changes as a result of a network or node failure.
在正常运行操作中,分区容忍一致性算法是很简单的。正如我们之前所说,如果我们不关心容错性,我们可以直接使用2PC算法。大部分情况下,算法复杂的原因就是因为我们需要保证一旦做出了一个一致性决策,它不能被丢失,并且有协议能够处理由于网络或节点崩溃带来的领导节点变化的情况
All nodes start as followers; one node is elected to be a leader at the start. During normal operation, the leader maintains a heartbeat which allows the followers to detect if the leader fails or becomes partitioned.
首先,刚开始的时候所有节点都是followers跟随者,然后其中一个节点被选举为leader领导者。在一个正常运行阶段,这个领导节点一直有心跳,允许其它跟随节点检测到它是否失败或者是被分区了
When a node detects that a leader has become non-responsive (or, in the initial case, that no leader exists), it switches to an intermediate state (called “candidate” in Raft) where it increments the term/epoch value by one, initiates a leader election and competes to become the new leader.
当一个节点检测到领导节点变得不响应时(或者,在最初的情况下,没有领导者存在),它会切换到一个中间状态(在raft中称为“候选人”),在这个状态中,它将周期纪元值增加一个,启动一个领导者选举,并竞争成为新的领导者
In order to be elected a leader, a node must receive a majority of the votes. One way to assign votes is to simply assign them on a first-come-first-served basis; this way, a leader will eventually be elected. Adding a random amount of waiting time between attempts at getting elected will reduce the number of nodes that are simultaneously attempting to get elected.
节点在投票过程中必须要获得多数投票才能成为一个领导节点。分配选票的最简单的一种方法是按先到先得的原则进行;这样,最终将选出一位领导节点。在选举过程中之间添加随机的等待时间将减少同时尝试当选的节点数
Numbered proposals within an epoch 一个周期中的编号提案
During each epoch, the leader proposes one value at a time to be voted upon. Within each epoch, each proposal is numbered with a unique strictly increasing number. The followers (voters / acceptors) accept the first proposal they receive for a particular proposal number.
在每一个周期纪元中,领导节点会依次提出一个值,用来供以表决。在每个周期中,每个提案都有一个唯一的严格递增的数字编号。追随者(投票者/接受者)接受他们收到的针对特定提案编号的第一个提案
Normal operation 正常运行
During normal operation, all proposals go through the leader node. When a client submits a proposal (e.g. an update operation), the leader contacts all nodes in the quorum. If no competing proposals exist (based on the responses from the followers), the leader proposes the value. If a majority of the followers accept the value, then the value is considered to be accepted.
在正常运行中,所有的提案会经过领导节点。当一个客户端提交一个提案(例如:一个更新操作),这个领导节点会联系仲裁中的所有的节点。如果没有竞争提案(基于追随者的响应),领导节点会提出一个值。如果大多数追随者接受这个值,那么这个值就被认为是被接受的
Since it is possible that another node is also attempting to act as a leader, we need to ensure that once a single proposal has been accepted, its value can never change. Otherwise a proposal that has already been accepted might for example be reverted by a competing leader. Lamport states this as:
P2: If a proposal with value
vis chosen, then every higher-numbered proposal that is chosen has valuev.
由于另一个节点也可能试图充当领导者,因此我们需要确保一旦接受了一个建议,它的值就永远不会改变。否则,一个已经被接受的提议可能会被竞争领导的节点回复。Lamport描述如下:
- P2: 如果一个提议的值一旦被确定为v,任何更高编号的提议也会选择这个值
Ensuring that this property holds requires that both followers and proposers are constrained by the algorithm from ever changing a value that has been accepted by a majority. Note that “the value can never change” refers to the value of a single execution (or run / instance / decision) of the protocol. A typical replication algorithm will run multiple executions of the algorithm, but most discussions of the algorithm focus on a single run to keep things simple. We want to prevent the decision history from being altered or overwritten.
确保追随者和提议者都不能改变已被大多数人接受的值。这里“值永远不能更改”是指协议的单个执行(或运行/实例/决策)的值。一个典型的复制算法将运行该算法的多个执行,但大多数关于该算法的讨论集中在一次运行上。我们希望防止更改或覆盖决策历史记录。
In order to enforce this property, the proposers must first ask the followers for their (highest numbered) accepted proposal and value. If the proposer finds out that a proposal already exists, then it must simply complete this execution of the protocol, rather than making its own proposal. Lamport states this as:
P2b. If a proposal with value
vis chosen, then every higher-numbered proposal issued by any proposer has valuev.
为了强制执行此属性,提案人必须首先向追随者询问他们(编号最高)接受的提案和值。如果提案人发现提案已经存在,那么它必须简单地完成协议的执行,而不是自己提出提案。Lamport描述如下:
- P2b. 如果一个提议的值一旦被确定为v,任何提议人发布的任何更高编号的提议都具有值v
More specifically:
P2c. For any
vandn, if a proposal with valuevand numbernis issued [by a leader], then there is a setSconsisting of a majority of acceptors [followers] such that either (a) no acceptor inShas accepted any proposal numbered less thann, or (b)vis the value of the highest-numbered proposal among all proposals numbered less thannaccepted by the followers inS.
更具体地说:
- P2c. 对于任何v和n,如果一个值为v编号为n的提案被[领导节点]发布,那么存在一个由大多数接受者[追随者]组成的集合S,其中,没有接受者接受编号比n小的提案,v是S中所有编号小于n的提案中编号最大的提案的值
This is the core of the Paxos algorithm, as well as algorithms derived from it. The value to be proposed is not chosen until the second phase of the protocol. Proposers must sometimes simply retransmit a previously made decision to ensure safety (e.g. clause b in P2c) until they reach a point where they know that they are free to impose their own proposal value (e.g. clause a).
这是paxos算法的核心,也是从中派生出来的算法的核心。在协议的第二阶段之前,不会对建议的值进行选择。提案人有时必须简单地重新传输先前做出的决定,以确保安全(例如P2c中的条款b),直到他们知道自己可以自由地强加自己的提案值(例如条款a)
If multiple previous proposals exist, then the highest-numbered proposal value is proposed. Proposers may only attempt to impose their own value if there are no competing proposals at all.
如果存在多个以前的建议,则建议使用编号最高的建议值。只有在完全没有竞争性提案的情况下,提案人才能试图强加自己的值
To ensure that no competing proposals emerge between the time the proposer asks each acceptor about its most recent value, the proposer asks the followers not to accept proposals with lower proposal numbers than the current one.
为了确保在提案人向每个接受人询问其最新值时不会出现竞争性提案,提案人要求跟随者不要接受提案编号低于当前提案编号的提案
Putting the pieces together, reaching a decision using Paxos requires two rounds of communication:
把这些部分放在一起,使用Paxos算法做出决定需要两轮通信:
1 | [ Proposer ] -> Prepare(n) [ Followers ] |
The prepare stage allows the proposer to learn of any competing or previous proposals. The second phase is where either a new value or a previously accepted value is proposed. In some cases - such as if two proposers are active at the same time (dueling); if messages are lost; or if a majority of the nodes have failed - then no proposal is accepted by a majority. But this is acceptable, since the decision rule for what value to propose converges towards a single value (the one with the highest proposal number in the previous attempt).
准备阶段允许提案人了解任何竞争或以前的提案。第二阶段是提出新值或先前接受的值。在某些情况下,例如,如果两个提议者同时处于活动状态(决斗);如果消息丢失;或者如果大多数节点都失败,则多数人不会接受任何提议。但这是可以接受的,因为建议的值的决策规则收敛到一个值(上一次尝试中建议数最高的值)。
Indeed, according to the FLP impossibility result, this is the best we can do: algorithms that solve the consensus problem must either give up safety or liveness when the guarantees regarding bounds on message delivery do not hold. Paxos gives up liveness: it may have to delay decisions indefinitely until a point in time where there are no competing leaders, and a majority of nodes accept a proposal. This is preferable to violating the safety guarantees.
事实上,根据FLP不可能的结果,这是我们所能做的最好的:解决共识问题的算法必须在消息传递边界的保证不成立时放弃安全性或活跃性。Paxos放弃了活跃性:它可能不得不无限期地推迟决策,直到某个时间点没有竞争的领导者,并且大多数节点都接受了一个提议。这比违反安全保证更可取。
Of course, implementing this algorithm is much harder than it sounds. There are many small concerns which add up to a fairly significant amount of code even in the hands of experts. These are issues such as:
- practical optimizations:
- avoiding repeated leader election via leadership leases (rather than heartbeats)
- avoiding repeated propose messages when in a stable state where the leader identity does not change
- ensuring that followers and proposers do not lose items in stable storage and that results stored in stable storage are not subtly corrupted (e.g. disk corruption)
- enabling cluster membership to change in a safe manner (e.g. base Paxos depends on the fact that majorities always intersect in one node, which does not hold if the membership can change arbitrarily)
- procedures for bringing a new replica up to date in a safe and efficient manner after a crash, disk loss or when a new node is provisioned
- procedures for snapshotting and garbage collecting the data required to guarantee safety after some reasonable period (e.g. balancing storage requirements and fault tolerance requirements)
Google’s Paxos Made Live paper details some of these challenges.
当然,实现这个算法要比听起来困难得多。有许多小问题,即使是在专家的手中,加起来也相当可观的代码量。这些问题包括:
- 实际优化:
– 通过领导权租赁(而不是心跳)避免重复的领导选举
– 避免在领导节点身份不变的稳定状态下重复建议消息 - 确保追随者和提议者不会丢失稳定存储中的项目,并且存储在稳定存储中的结果不会被损坏(例如磁盘损坏)。
- 允许集群成员以安全的方式进行更改(例如,基本Paxos依赖于一个事实:大多数成员总是在一个节点中相交,如果成员可以任意更改,那么这个节点就不起作用)
- 在崩溃、磁盘丢失或配置新节点后以安全有效的方式使新副本更新的过程
- 快照和垃圾收集程序:在一段合理的时间后,为确保安全所需的数据(例如,平衡存储要求和容错要求)
谷歌的Paxos制作了实况文件,详细介绍了其中的一些挑战
Partition-tolerant consensus algorithms: Paxos, Raft, ZAB
分区容忍一致性算法:Paxos、Raft、ZAB
Hopefully, this has given you a sense of how a partition-tolerant consensus algorithm works. I encourage you to read one of the papers in the further reading section to get a grasp of the specifics of the different algorithms.
这一节想让您了解了一个允许分区的共识算法是如何工作的。鼓励大家阅读下一阅读部分中的文章,以了解不同算法的具体情况。
Paxos. Paxos is one of the most important algorithms when writing strongly consistent partition tolerant replicated systems. It is used in many of Google’s systems, including the Chubby lock manager used by BigTable/Megastore, the Google File System as well as Spanner.
Paxos-是在编写强一致性的容错分区复制系统时最重要的算法之一。它被用于谷歌的许多系统,包括Bigtable/MegaStore使用的丰满版锁管理器、谷歌文件系统以及Spanner
Paxos is named after the Greek island of Paxos, and was originally presented by Leslie Lamport in a paper called “The Part-Time Parliament” in 1998. It is often considered to be difficult to implement, and there have been a series of papers from companies with considerable distributed systems expertise explaining further practical details (see the further reading). You might want to read Lamport’s commentary on this issue here and here.
Paxos以希腊的帕克斯岛命名,最初由莱斯利·兰波特于1998年在一份名为“兼职议会”的论文中提出。它通常被认为是很难实现的,具有相当多分布式系统专业知识的公司的一系列论文对其具体实施的实际细节进行了进一步的解释(请参阅进一步阅读)
The issues mostly relate to the fact that Paxos is described in terms of a single round of consensus decision making, but an actual working implementation usually wants to run multiple rounds of consensus efficiently. This has led to the development of many extensions on the core protocol that anyone interested in building a Paxos-based system still needs to digest. Furthermore, there are additional practical challenges such as how to facilitate cluster membership change.
我们使用一轮共识决策来描述Paxos算法,但是实际的工作执行通常希望高效地运行多轮共识。这导致了核心协议上的许多扩展的开发,任何对构建基于Paxos的系统感兴趣的人仍然需要消化这些扩展。此外,还有一些额外的实际挑战,例如如何促进集群成员资格的改变。
ZAB. ZAB - the Zookeeper Atomic Broadcast protocol is used in Apache Zookeeper. Zookeeper is a system which provides coordination primitives for distributed systems, and is used by many Hadoop-centric distributed systems for coordination (e.g. HBase, Storm, Kafka). Zookeeper is basically the open source community’s version of Chubby. Technically speaking atomic broadcast is a problem different from pure consensus, but it still falls under the category of partition tolerant algorithms that ensure strong consistency.
ZAB-在Apache ZooKeeper中使用了ZooKeeper原子广播协议。ZooKeeper是为分布式系统提供协调原语的系统,许多以Hadoop为中心的分布式系统(如HBase、Storm、Kafka)都使用它进行协调。ZooKeeper基本上是开源社区的丰满版本。从技术上讲,原子广播是一个不同于纯一致共识的问题,但它仍然属于保证强一致性的分区容忍算法范畴。
Raft. Raft is a recent (2013) addition to this family of algorithms. It is designed to be easier to teach than Paxos, while providing the same guarantees. In particular, the different parts of the algorithm are more clearly separated and the paper also describes a mechanism for cluster membership change. It has recently seen adoption in etcd inspired by ZooKeeper.
Raft-Raft是最近(2013年)对该算法系列的一个补充。它被设计成比Paxos更容易教学,同时提供相同的保证。特别是算法的不同部分之间的分离更加清晰,本文还描述了一种集群成员关系变化的机制。它最近在受ZooKeeper启发的etcd中被采用。
Replication methods with strong consistency 强一致性的复制方法
In this chapter, we took a look at replication methods that enforce strong consistency. Starting with a contrast between synchronous work and asynchronous work, we worked our way up to algorithms that are tolerant of increasingly complex failures. Here are some of the key characteristics of each of the algorithms:
在本章中,我们介绍强制实现强一致性的复制方法。从同步工作和异步工作之间的对比开始,我们了解能够容忍日益复杂的故障的算法。以下是每种算法的一些关键特性:
Primary/Backup
- Single, static master
- Replicated log, slaves are not involved in executing operations
- No bounds on replication delay
- Not partition tolerant
- Manual/ad-hoc failover, not fault tolerant, “hot backup”
主/备算法
- 单,静态主机
- 复制的日志,从服务器不参与执行操作
- 复制延迟没有限制
- 不允许分区
- 手动/故障转移,不容错,“热备份”
2PC
- Unanimous vote: commit or abort
- Static master
- 2PC cannot survive simultaneous failure of the coordinator and a node during a commit
- Not partition tolerant, tail latency sensitive
2PC
- 一致表决:同意或放弃
- 静态主机
- 2PC在提交过程中无法承受协调器和节点的同时失败。
- 不允许分区,尾延迟敏感
Paxos
- Majority vote
- Dynamic master
- Robust to n/2-1 simultaneous failures as part of protocol
- Less sensitive to tail latency
Paxos
- 多数投票机制
- 动态主机
- 作为协议的一部分,对N/2-1同时故障具有鲁棒性
- 对尾延迟不太敏感
Further reading
Primary-backup and 2PC
- Replication techniques for availability - Robbert van Renesse & Rachid Guerraoui, 2010
- Concurrency Control and Recovery in Database Systems
Paxos
- The Part-Time Parliament - Leslie Lamport
- Paxos Made Simple - Leslie Lamport, 2001
- Paxos Made Live - An Engineering Perspective - Chandra et al
- Paxos Made Practical - Mazieres, 2007
- Revisiting the Paxos Algorithm - Lynch et al
- How to build a highly available system with consensus - Butler Lampson
- Reconfiguring a State Machine - Lamport et al - changing cluster membership
- Implementing Fault-Tolerant Services Using the State Machine Approach: a Tutorial - Fred Schneider
Raft and ZAB
- In Search of an Understandable Consensus Algorithm, Diego Ongaro, John Ousterhout, 2013
- Raft Lecture - User Study
- A simple totally ordered broadcast protocol - Junqueira, Reed, 2008
- ZooKeeper Atomic Broadcast - Reed, 2011